Buchstabenhäufigkeit
Die Buchstabenhäufigkeit (Graphemhäufigkeit) ist eine statistische Größe, die angibt, wie oft ein bestimmter Buchstabe in einem Text oder einer Sammlung von Texten (Korpus) vorkommt. Sie kann als absolute Anzahl oder in Relation zur Gesamtzahl der Buchstaben des Textes angegeben werden. Die Häufigkeitsverteilung der Buchstaben hängt von der jeweiligen Sprache ab. Während frühere Annahmen pauschal die statistische Verteilung der Buchstabenhäufigkeit durch das Zipfsche Gesetz vorherzusagen glaubten, hat die quantitative Linguistik gezeigt, dass eine Reihe anderer Wahrscheinlichkeitsverteilungen[1] in Betracht zu ziehen sind. Zählungen zur Häufigkeit von Buchstaben oder Lauten in Texten oder Textkorpora sind spätestens seit dem frühen 19. Jahrhundert nachweisbar.[2] Für manche Zwecke ist es auch interessant, wie häufig ein Buchstabe am Wortanfang oder am Wortende vorkommt.
Anwendung
[Bearbeiten | Quelltext bearbeiten]Die Buchstabenhäufigkeit wird in der Entschlüsselung von Substitutionsverfahren in der Kryptoanalyse sowie in der Datenkompression und -kodierung benutzt. Bei einfachen Verschlüsselungsverfahren wie bei der Cäsarchiffre kann ein Geheimtext alleine durch Häufigkeitsanalyse entschlüsselt werden. Dabei werden die Häufigkeiten der einzelnen Zeichen im Geheimtext festgestellt und dann mit der Häufigkeit der Zeichen in einem Klartext der vermuteten Sprache verglichen. Nun werden die Buchstaben des Geheimtextes durch die normalen Buchstaben gleicher Häufigkeit ersetzt. Der häufigste Buchstabe des Geheimtextes entspricht dann zum Beispiel dem Klartextbuchstaben e. Diese Methode ist offensichtlich für längere zu entschlüsselnde Texte besonders gut geeignet, weil die statistische Abweichung der gefundenen Buchstabenhäufigkeit von der zu erwartenden Häufigkeit geringer wird.
Für den Maschinenschreibunterricht ist es wichtig, dass die Lehrkraft über die Buchstabenhäufigkeit in einer Sprache gut informiert ist und die Unterrichtsinhalte entsprechend darauf abgestimmt werden. Häufige Buchstaben wie das E oder das I müssen hinreichend trainiert werden, um eine möglichst hohe Anschlagszahl und eine gute Schreibsicherheit zu erzielen. Bei der Erstellung ergonomischer Tastaturbelegungen spielt die Buchstabenhäufigkeit ebenfalls eine große Rolle. Hersteller von Buchstabenspielen wie Boggle oder Scrabble berücksichtigen bei den nationalen Varianten ebenfalls die Häufigkeit und, falls vorhanden, auch die Wertigkeit der Buchstaben.
Eine der ersten Anwendungen war das Morse-Alphabet, das für häufige Zeichen kurze Codes verwendet (zum Beispiel E = ·); für selten gebrauchte Zeichen dagegen längere Codes (zum Beispiel Q = – – · –).
Weiterführung
[Bearbeiten | Quelltext bearbeiten]Die Weiterführung der Buchstabenhäufigkeit ist die Häufigkeit von Buchstabenpaaren und -tripeln und die Worthäufigkeit sowie von Schrifteinheiten, die für eine systematische Lauteinheit stehen (Grapheme für Phoneme). Befasst man sich statt mit der geschriebenen einmal mit der gesprochenen Sprache, so kann man ganz entsprechend auch Erhebungen zur Laut- oder Phonemhäufigkeit durchführen.
Buchstabenhäufigkeit in deutschsprachigen Texten
[Bearbeiten | Quelltext bearbeiten]Aus der folgenden Tabelle lässt sich rechnerisch ableiten, dass mit den fünf häufigsten Buchstaben rund die Hälfte, und mit den zehn häufigsten Buchstaben dreiviertel der Buchstabenhäufigkeit in deutschsprachigen Texten abgedeckt ist. Die Umlaute ä, ö und ü wurden wie ae, oe und ue gezählt, ß als eigenständiges Zeichen.[3]
| Platz | Buchstabe | Relative Häufigkeit |
|---|---|---|
| 1. | E | 17,40 % |
| 2. | N | 9,78 % |
| 3. | I | 7,55 % |
| 4. | S | 7,27 % |
| 5. | R | 7,00 % |
| 6. | A | 6,51 % |
| 7. | T | 6,15 % |
| 8. | D | 5,08 % |
| 9. | H | 4,76 % |
| 10. | U | 4,35 % |
| 11. | L | 3,44 % |
| 12. | C | 3,06 % |
| 13. | G | 3,01 % |
| 14. | M | 2,53 % |
| 15. | O | 2,51 % |
| 16. | B | 1,89 % |
| 17. | W | 1,89 % |
| 18. | F | 1,66 % |
| 19. | K | 1,21 % |
| 20. | Z | 1,13 % |
| 21. | P | 0,79 % |
| 22. | V | 0,67 % |
| 23. | ẞ | 0,31 % |
| 24. | J | 0,27 % |
| 25. | Y | 0,04 % |
| 26. | X | 0,03 % |
| 27. | Q | 0,02 % |
Bei einer Gleichverteilung der 27 Buchstaben betrüge die relative Häufigkeit jeweils 3,704 %.
Zum Vergleich eine Datei, die auf 99.586 Buchstaben eines gemischten Briefkorpus einer Person (Korrespondenz mit Ämtern, Freunden, Kollegen, Rundfunkanstalten, Verlagen…; immer nur der laufende Text, also ohne Briefkopf, Anrede und Grußformel; Briefe aus den Jahren 1996–2004) beruht. Im Unterschied zur vorigen Übersicht sind die Umlautbuchstaben <ä>, <ö> und <ü> je für sich erhoben.[4]
| Platz | Buchstabe | Absolute Häufigkeit | Relative Häufigkeit |
|---|---|---|---|
| 1. | E | 16.040 | 16,11 % |
| 2. | N | 10.288 | 10,33 % |
| 3. | I | 9.011 | 9,05 % |
| 4. | R | 6.693 | 6,72 % |
| 5. | T | 6.312 | 6,34 % |
| 6. | S | 6.203 | 6,23 % |
| 7. | A | 5.577 | 5,60 % |
| 8. | H | 5.177 | 5,20 % |
| 9. | D | 4.156 | 4,17 % |
| 10. | U | 3.680 | 3,70 % |
| 11. | C | 3.384 | 3,40 % |
| 12. | L | 3.226 | 3,24 % |
| 13. | G | 2.924 | 2,94 % |
| 14. | M | 2.784 | 2,80 % |
| 15. | O | 2.312 | 2,32 % |
| 16. | B | 2.176 | 2,19 % |
| 17. | F | 1.701 | 1,71 % |
| 18. | W | 1.383 | 1,39 % |
| 19. | Z | 1.351 | 1,36 % |
| 20. | K | 1.329 | 1,33 % |
| 21. | V | 912 | 0,92 % |
| 22. | P | 841 | 0,84 % |
| 23. | Ü | 636 | 0,64 % |
| 24. | Ä | 511 | 0,51 % |
| 25. | Ö | 363 | 0,36 % |
| 26. | ẞ | 189 | 0,19 % |
| 27. | J | 186 | 0,19 % |
| 28. | X | 112 | 0,11 % |
| 29. | Q | 73 | 0,07 % |
| 30. | Y | 56 | 0,06 % |
Das Institut für Deutsche Sprache in Mannheim bietet auf seinen Seiten diverse Zeichen- und Buchstabenhäufigkeitslisten zum Download an.[5] Den Statistiken liegt eine Textstichprobe von knapp 180 Milliarden Zeichen aus dem Deutschen Referenzkorpus zugrunde (Stand 2018).
Eine Übersicht über die Buchstabenhäufigkeit in Form eines Balkendiagramms bietet Duden auf der Grundlage des Duden-Korpus, einer Volltextsammlung mit über 2 Milliarden Wortformen; auch in dieser Übersicht werden die Umlautbuchstaben je für sich aufgelistet.[6] Die Graphik wurde in der 27. Auflage des Rechtschreib-Duden überarbeitet, jetzt auf der Grundlage des Duden-Korpus mit inzwischen 4 Milliarden Wortformen (Stand Frühjahr 2017).[7]
Anfangsbuchstaben
[Bearbeiten | Quelltext bearbeiten]Die Häufigkeit von Anfangsbuchstaben gibt an, wie oft ein Buchstabe als erster Buchstabe eines Wortes vorkommt. Sie hängt relativ stark von der Textart ab. Für Fließtext sind die fünf häufigsten Anfangsbuchstaben:[8]
| Platz | Buchstabe | Relative Häufigkeit |
|---|---|---|
| 1. | D | 14,2 % |
| 2. | S | 10,8 % |
| 3. | E | 7,8 % |
| 4. | I | 7,1 % |
| 5. | W | 6,8 % |
Für Lexika ergibt sich eine andere Verteilung. Die Buchstaben D, E, I und W kommen im Vergleich zum Fließtext wesentlich seltener am Wortanfang vor, S kommt mit deutlichem Abstand am häufigsten vor:[8]
| Platz | Buchstabe | Relative Häufigkeit |
|---|---|---|
| 1. | S | 11,8 % |
| 2. | K | 7,3 % |
| 3. | A | 7,1 % |
| 4. | P | 7,0 % |
| 5. | B | 5,7 % |
| 6. | M | 5,7 % |
Endbuchstaben
[Bearbeiten | Quelltext bearbeiten]Die Häufigkeit von Endbuchstaben gibt an, wie häufig ein Buchstabe als letzter Buchstabe eines Wortes vorkommt. (Als Beispiel-Textbasis wurde der Roman Effi Briest von Theodor Fontane ausgewertet, wobei ß stets als ss gezählt wurde. Die Textbasis umfasst alle 36 Kapitel dieses Werks mit insgesamt 572.849 Zeichen.)
| Platz | Buchstabe | Relative Häufigkeit |
|---|---|---|
| 1. | N | 21,0 % |
| 2. | E | 15,1 % |
| 3. | R | 13,0 % |
| 4. | T | 10,3 % |
| 5. | S | 9,6 % |
Häufigkeitsdiagramme
[Bearbeiten | Quelltext bearbeiten]-
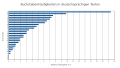 Diagramm zu der relativen Buchstabenhäufigkeit in deutschsprachigen Texten
Diagramm zu der relativen Buchstabenhäufigkeit in deutschsprachigen Texten -
 Monogramm-Häufigkeitsgebirge: Die Buchstaben-Häufigkeitsverteilung eines längeren deutschen Textes.
Monogramm-Häufigkeitsgebirge: Die Buchstaben-Häufigkeitsverteilung eines längeren deutschen Textes. -
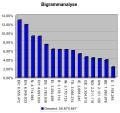 Bigramm-Häufigkeitsgebirge: Verteilung der häufigsten Bigramme in einem deutschen Text.
Bigramm-Häufigkeitsgebirge: Verteilung der häufigsten Bigramme in einem deutschen Text. -
![Trigramm-Häufigkeitsgebirge: Verteilung der häufigsten Trigramme in einem deutschen Text. Die Tripel ER_ und EN_ sind am häufigsten [_ steht für das Leerzeichen].](//upload.wikimedia.org/wikipedia/de/thumb/2/2f/Alphabet_trigramm.svg/120px-Alphabet_trigramm.svg.png) Trigramm-Häufigkeitsgebirge: Verteilung der häufigsten Trigramme in einem deutschen Text. Die Tripel ER_ und EN_ sind am häufigsten [_ steht für das Leerzeichen].
Trigramm-Häufigkeitsgebirge: Verteilung der häufigsten Trigramme in einem deutschen Text. Die Tripel ER_ und EN_ sind am häufigsten [_ steht für das Leerzeichen]. -
-




![Trigramm-Häufigkeitsgebirge: Verteilung der häufigsten Trigramme in einem deutschen Text. Die Tripel ER_ und EN_ sind am häufigsten [_ steht für das Leerzeichen].](/wiki/Datei:Alphabet_trigramm.svg)


Buchstabenhäufigkeit in ausgewählten Sprachen
[Bearbeiten | Quelltext bearbeiten]| Buchstabe | Deutsch | Englisch[9] | Französisch[10] | Spanisch[11] | Esperanto[12] | Italienisch[13] | Schwedisch[14] | Polnisch[15] |
|---|---|---|---|---|---|---|---|---|
| a | 6,51 % | 8,167 % | 7,636 % | 12,53 % | 12,12 % | 11,74 % | 9,3 % | 8,0 % |
| b | 1,89 % | 1,492 % | 0,901 % | 1,42 % | 0,98 % | 0,92 % | 1,3 % | 1,3 % |
| c | 3,06 % | 2,782 % | 3,260 % | 4,68 % | 0,78 % | 4,5 % | 1,3 % | 3,8 % |
| d | 5,08 % | 4,253 % | 3,669 % | 5,86 % | 3,04 % | 3,73 % | 4,5 % | 3,0 % |
| e | 17,40 % | 12,702 % | 14,715 % | 13,68 % | 8,99 % | 11,79 % | 9,9 % | 6,9 % |
| f | 1,66 % | 2,228 % | 1,066 % | 0,69 % | 1,03 % | 0,95 % | 2,0 % | 0,1 % |
| g | 3,01 % | 2,015 % | 0,866 % | 1,01 % | 1,17 % | 1,64 % | 3,3 % | 1,0 % |
| h | 4,76 % | 6,094 % | 0,737 % | 0,70 % | 0,38 % | 1,54 % | 2,1 % | 1,0 % |
| i | 7,55 % | 6,966 % | 7,529 % | 6,25 % | 10,01 % | 11,28 % | 5,1 % | 7,0 % |
| j | 0,27 % | 0,153 % | 0,545 % | 0,44 % | 3,50 % | 0,00 % | 0,7 % | 1,9 % |
| k | 1,21 % | 0,772 % | 0,049 % | 0,00 % | 4,16 % | 0,00 % | 3,2 % | 2,7 % |
| l | 3,44 % | 4,025 % | 5,456 % | 4,97 % | 6,14 % | 6,51 % | 5,2 % | 3,1 % |
| m | 2,53 % | 2,406 % | 2,968 % | 3,15 % | 2,99 % | 2,51 % | 3,5 % | 2,4 % |
| n | 9,78 % | 6,749 % | 7,095 % | 6,71 % | 7,96 % | 6,88 % | 8,8 % | 4,7 % |
| o | 2,51 % | 7,507 % | 5,378 % | 8,68 % | 8,78 % | 9,83 % | 4,1 % | 7,1 % |
| p | 0,79 % | 1,929 % | 3,021 % | 2,51 % | 2,74 % | 3,05 % | 1,7 % | 2,4 % |
| q | 0,02 % | 0,095 % | 1,362 % | 0,88 % | 0,00 % | 0,51 % | 0,007 % | 0,00 % |
| r | 7,00 % | 5,987 % | 6,553 % | 6,87 % | 5,91 % | 6,37 % | 8,3 % | 3,5 % |
| s | 7,27 % | 6,327 % | 7,948 % | 7,98 % | 6,09 % | 4,98 % | 6,3 % | 3,8 % |
| t | 6,15 % | 9,056 % | 7,244 % | 4,63 % | 5,27 % | 5,62 % | 8,7 % | 2,4 % |
| u | 4,35 % | 2,758 % | 6,311 % | 3,93 % | 3,18 % | 3,01 % | 1,8 % | 1,8 % |
| v | 0,67 % | 0,978 % | 1,628 % | 0,90 % | 1,90 % | 2,10 % | 2,4 % | 0,00 % |
| w | 1,89 % | 2,360 % | 0,114 % | 0,02 % | 0,00 % | 0,00 % | 0,03 % | 3,6 % |
| x | 0,03 % | 0,150 % | 0,387 % | 0,22 % | 0,00 % | 0,00 % | 0,1 % | 0,00 % |
| y | 0,04 % | 1,974 % | 0,308 % | 0,90 % | 0,00 % | 0,00 % | 0,6 % | 3,2 % |
| z | 1,13 % | 0,074 % | 0,136 % | 0,52 % | 0,50 % | 0,49 % | 0,02 % | 5,1 % |
| œ | 0,00 % | 0,00 % | 0,018 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ß | 0,31 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| à | 0,00 % | 0,00 % | 0,486 % | 0,00 % | 0,00 % | siehe a | 0,00 % | 0,00 % |
| ą | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe a |
| ç | 0,00 % | 0,00 % | 0,085 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ĉ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,66 % | 0,00 % | 0,00 % | 0,00 % |
| ć | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe c |
| è | 0,00 % | 0,00 % | 0,271 % | 0,00 % | 0,00 % | siehe e | 0,00 % | 0,00 % |
| é | 0,01 % | 0,00 % | 1,904 % | 0,00 % | 0,00 % | siehe e | 0,00 % | 0,00 % |
| ê | 0,00 % | 0,00 % | 0,225 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ë | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ę | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe e |
| ĝ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,69 % | 0,00 % | 0,00 % | 0,00 % |
| ĥ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,02 % | 0,00 % | 0,00 % | 0,00 % |
| î | 0,00 % | 0,00 % | 0,045 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ì | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe i | 0,00 % | 0,00 % |
| ï | 0,00 % | 0,01 % | 0,005 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ĵ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,12 % | 0,00 % | 0,00 % | 0,00 % |
| ł | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe l |
| ń | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe n |
| ó | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe o |
| ò | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe o | 0,00 % | 0,00 % |
| ŝ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,38 % | 0,00 % | 0,00 % | 0,00 % |
| ś | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe s |
| ù | 0,00 % | 0,00 % | 0,058 % | 0,00 % | 0,00 % | siehe u | 0,00 % | 0,00 % |
| ŭ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,52 % | 0,00 % | 0,00 % | 0,00 % |
| ź | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe z |
| ż | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,7 % |
Besonders bemerkenswert in der Tabelle ist, dass im Deutschen der Buchstabe E deutlich häufiger und der Buchstabe O deutlich seltener angewendet werden als in romanischen und slawischen Sprachen.
Die Tabelle stellt nur die Häufigkeiten von Buchstaben in Texten/Korpora von Sprachen dar, für die die lateinische Schrift verwendet wird. Zur Buchstabenhäufigkeit in Sprachen mit der kyrillischen Schrift kann auf die Darstellung von Kempgen (1995) zum Russischen[16] und die Untersuchung von Grzybek & Kehlich (2005) zum Ukrainischen verwiesen werden.[17]
Siehe auch
[Bearbeiten | Quelltext bearbeiten]- Benfordsches Gesetz (Ziffernhäufigkeit)
- Häufigkeitsklasse
- Lauthäufigkeit
- Phonemhäufigkeit
- Worthäufigkeit
- N-Gramm
Literatur
[Bearbeiten | Quelltext bearbeiten]- Friedrich L. Bauer: Entzifferte Geheimnisse. Methoden und Maximen der Kryptologie. Springer, Berlin u. a. 1995, ISBN 3-540-58118-9. (Enthält Buchstabenhäufigkeiten im Deutschen und Englischen mit Prozentangaben auf Seite 223.)
- Karl-Heinz Best: Zur Häufigkeit von Buchstaben, Leerzeichen und anderen Schriftzeichen in deutschen Texten. In: Glottometrics. 11, 2005, S. 9–31; ram-verlag.eu (PDF; 1,6 MB); ISSN 1617-8351 (gibt neben den Buchstabenhäufigkeiten auch die Anteile anderer Zeichen in deutschen Texten an).
- Erich Mater: Deutsche Verben. 1. Alphabetisches Verzeichnis. Bibliographisches Institut, Leipzig 1966. (Enthält im Anfangskapitel eine Übersicht über die Häufigkeit von Anfangsbuchstaben in 6 verschiedenen Wörterbüchern sowie eine Gesamtübersicht. Leider keine Seitenzählung.)
- Helmut Meier: Deutsche Sprachstatistik (= Olms Paperbacks. 31). 2., erweiterte und verbesserte Auflage. Olms, Hildesheim 1967. (Buchstabenstatistik des Deutschen, Englischen und Spanischen auf S. 334.)
- Gustav Muthmann: Rückläufiges deutsches Wörterbuch. Handbuch der Wortausgänge im Deutschen, mit Beachtung der Wort- und Lautstruktur (= Reihe germanistische Linguistik. 78). Niemeyer, Tübingen 1988, ISBN 3-484-31078-2. (Enthält auf Seite 36 eine Zusammenstellung der Häufigkeiten von Anfangsbuchstaben sowie Seite 65 der Endbuchstaben.)
- Gustav Muthmann: Phonologisches Wörterbuch der deutschen Sprache (= Reihe Germanistische Linguistik. 163). Niemeyer, Tübingen 1996, ISBN 3-484-31163-0, Seite 35–37. (Häufigkeit von Graphemen und Phonemen.)
- Wolfgang Schönpflug: n-Gramm-Häufigkeit in der deutschen Sprache. I. Monogramme und Digramme. In: Zeitschrift für experimentelle und angewandte Psychologie. 16, 1969, ISSN 0044-2712, Seite 157–183. (Enthält auf Seite 162f. eine Übersicht über die Häufigkeit von Buchstaben in einem Textkorpus von über 100.000 Wörtern, getrennt nach der Position im Wort.)
- Katja Siekmann, Günther Thomé: Der orthographische Fehler. 2., aktualisierte Aufl. Oldenburg 2018, ISBN 978-3-942122-07-8 (enthält auf den Seiten 239 bis 247 ausführliche Übersichten über die Häufigkeit von Buchstaben und Buchstabenverbindungen aus einer neueren 100.000-er Auszählung von Phonem-Graphem-Korrespondenzen im Deutschen. isb-Verlag Oldenburg).
- Dorothea Thomé, Günther Thomé: Phoneme und Grapheme im Deutschen: drei Schaubilder. 1. Die Laute des Deutschen (nach der Standardlautung), 2. Basisgrapheme (grundlegende Schriftzeichen für Phoneme), 3. Alle Basis- und Orthographeme (Was ist wie häufig?). isb-Fachverlag, Oldenburg 2014, ISBN 978-3-942122-15-3.
- Günther Thomé, Dorothea Thomé: Deutsche Wörter nach Laut- und Schrifteinheiten gegliedert. 2., bearbeitete Auflage, isb-Fachverlag, Oldenburg 2023, ISBN 978-3-942122-43-6 (Leseproben unter isb-Verlag Oldenburg; Mit zahlreichen Tabellen über die Häufigkeit der Laut- und Schrifteinheiten im Deutschen.)
Weblinks
[Bearbeiten | Quelltext bearbeiten]- Korpusbasierte Zeichenhäufigkeitslisten am Institut für Deutsche Sprache, Mannheim
- Grazer Projekt zur Quantitativen Textanalyse (QuanTA)
- Bibliographien und weitere Informationen zum Göttinger Projekt Quantitative Linguistik
- Portables Freeware-Tool um die Häufigkeiten von Buchstaben und/oder Silben aus beliebig langen Texten zu bestimmen
Einzelnachweise
[Bearbeiten | Quelltext bearbeiten]- ↑ S. dazu: lql.uni-trier.de ( vom 7. April 2015 im Internet Archive) Buchstaben, Laute und Phoneme folgen im Prinzip den gleichen Verteilungen.
- ↑ Karl-Heinz Best: Laut- und Buchstabenzählungen im frühen 19. Jahrhundert. In: Glottometrics, 20, 2010, S. 110–114; ram-verlag.eu (PDF; 1,8 MB).
- ↑ Albrecht Beutelspacher: Kryptologie. 7. Auflage. Vieweg Verlagsgesellschaft, Wiesbaden 2005, ISBN 3-8348-0014-7, Seite 10.
- ↑ Karl-Heinz Best: Buchstabenhäufigkeiten im Deutschen und Englischen. In: Naukovyj Visnyk Černivec'koho Universitetu. Vypusk 231, 2005, ZDB-ID 2390772-1, S. 119–127.
- ↑ Korpuslinguistik: Korpusbasierte Zeichen- und Buchstabenhäufigkeitslisten. Institut für Deutsche Sprache, abgerufen am 20. März 2018 (deutsch).
- ↑ Duden – Deutsches Universalwörterbuch. 7., überarbeitete und erweiterte Auflage. Dudenverlag, Mannheim/Zürich 2011, ISBN 978-3-411-05507-4, Seite 2110.
- ↑ Duden. Die deutsche Rechtschreibung. 27., völlig neu bearbeitete und erweiterte Auflage. Dudenverlag, Berlin 2017, ISBN 978-3-411-04017-9, Seite 148, 158.
- ↑ a b Peter Vogelgesang: Häufigkeit von Buchstaben. ( vom 9. Februar 2006 im Internet Archive) 2003.
- ↑ Robert Edward Lewand: Relative Frequencies of Letters in General English Plain text.
- ↑ CorpusDeThomasTempé. ( vom 13. Februar 2008 im Internet Archive)
- ↑ Fletcher Pratt: Secret and Urgent: the Story of Codes and Ciphers Blue Ribbon Books, 1939, Seite 254–255.
- ↑ La Oftecoj de la Esperantaj Literoj. Abgerufen am 14. September 2007.
- ↑ Simon Singh: Codici e Segreti. RCS, 1999, ISBN 88-17-12539-3.
- ↑ Simon Singh: Brogren Margareta: Kodboken: konsten att skapa sekretess – från det gamla Egypten till kvantkryptering. Norstedt, Stockholm 1999, ISBN 91-1-300708-4.
- ↑ Wstęp do kryptologii. (MS Word; 300 kB) Abgerufen am 30. April 2012.
- ↑ Sebastian Kempgen: Russische Sprachstatistik. Systematischer Überblick und Bibliographie. Verlag Otto Sagner, München 1995, ISBN 3-87690-617-2, S. 19–22.
- ↑ Peter Grzybek, Emmerich Kelih: Graphemhäufigkeiten im Ukrainischen. Teil I: Ohne Apostroph ('). In: Gabriel Altmann, Viktor Levickij, & Valentina Perebyinis (Hrsg.): Problemy kvantytatyvnoi linhvistyky / Problems of Quantitative Linguistics: zbirnyk naukovych prac. Ruta, Cernivci 2005, ISBN 966-568-783-2, S. 159–179.